Dear Psi4 Team,
Hope you’re doing well. We’ve been evaluating Psi4 on our HPC systems and wanted to check a few observations with you before investing further effort. Our hardware includes AMD EPYC “Milan” 7713 CPU nodes and AMD MI250X GPU nodes.
What we’ve observed so far
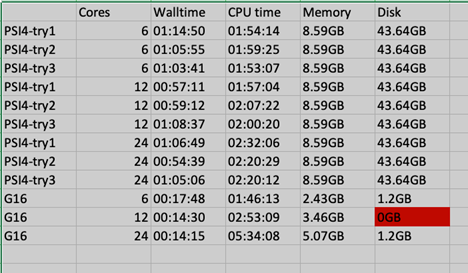
- For a moderately sized single-point calculation (cc-pVTZ), our initial benchmarks show high memory and disk usage compared with what we’d expect for this problem size. Although not on the benchmark, utilising the aug-cc-pVTZ basis set resulted in 2-3x memory demand. I’ve attached a table with a few job runs (wall time, CPU time, memory, disk) for reference.
- Profiling shows a fairly deep stack of Python-level calls (lots of short tasks) and relatively small OpenMP parallel regions. This makes it hard to get good use of all the cores on a node. It also complicates attempts to send bigger workloads to GPUs, since ideally we’d want fewer, larger parallel regions rather than lots of small ones.
- We found a related forum thread that suggests Psi4 may not be the best fit for some HPC installs: Suggestions for HPC installation?. We wanted to check if we’re understanding that correctly.
A few questions
- Are there build/runtime options you’d recommend to help reduce peak memory and disk usage for this benchmark?
- Is Psi4’s current parallelism model expected to break work into many short Python-dispatched tasks with small OpenMP regions? If so, are there ways you’d suggest to improve overall CPU core use on a node?
- On GPU offload: are there plans or ongoing efforts to make Psi4 (or key computational kernels it uses) more GPU-friendly? If not, do you see a practical path toward that model?
- Do you know of HPC sites currently running Psi4 successfully? We’d be keen to reach out and learn from their setup.
Thanks for any guidance you can share.
The input file we ran is attached as well. Thank you for your work.
input.dat (2.6 KB)